Autocode Suggestion using GPT2
Index
Autocode - Video
Keywords: Transfer Learning of model, GPT-2.
Introduction
"Time to Market" is key ingradient for success of any product in recent times. In current industry scenario in Software Engineering, especially software development with programming languages most critical part of project execution and plays a major role. While working for objectives, Lower-level software programming takes majority of time and has impact on quality of deliverables. Almost all the software organizations must deal with software programming problems like bugs, error and other complexities while working on complex software.
Auto Code Generation or Suggestion tools can assist the software development process and improve programmer's productivity with lesser errors and with less critical defects within low impact on production.
Already, There are some IDE based code generator are available in market like tabnine, kite & github co-pilot, but they do not target specific industry area and support general programming requirements. In this blog, we will focus on the Code Generation with C programming language.
Language modelling will be used to generate Auto-code suggestion based on sample code in C programming language.
System Overview
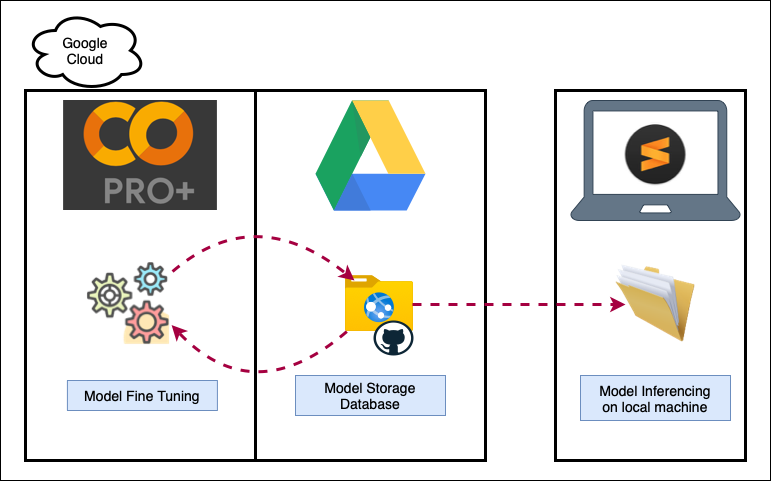
Overall System (Model Transfer Learning and inferencing) includes below components
GPT2 Architecture
Since the Generative Pre-trained Transformer (GPT-2) model is complicated and vast, we only present the basic information needed to enable the reader to comprehend the paper and understand the proposed Auto Code suggestion solution presented in this research.
GPT is short for Generative Pre-Training provided by OpenAI for Casual Language Modelling that can predict the next token in a sequence. Therefore, it can generate source code based on the input. For tokenization Byte Pair encoding is used
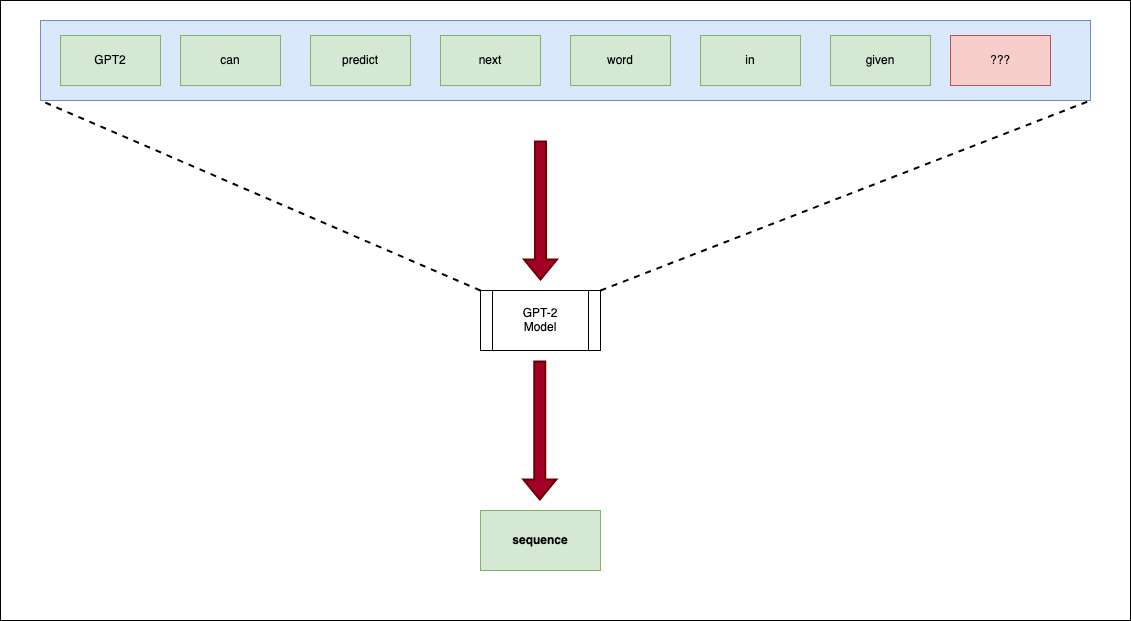
GPT-2 is trained on massive 40GB WebText dataset which makes it suitable to generate or predict sequence of words and we will use it to Transfer Learning with C Programming dataset.
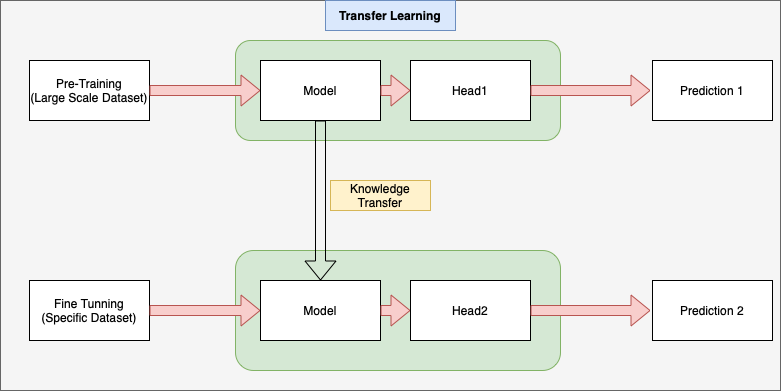
Transfer learning with transformer model, In pre-training phase, weights are updated from random initialization to fit to perform pre-defined tasks such as sequence generation and in Transfer Learning process for model, weights are adjusted so that model fit to perform specific task.
There are following types of GPT2 models will be under our scope:
- Distil GPT2 with 83M parameters
- GPT2 with 117M Parameters
- GPT2 Medium with 345M Parameters
Generally, transformer-based language models are based on encoder and decoder stacks and GPT2 models are based on decoder stacks. Normally decoder block contains Masked attention block (Ashish Vaswani, 2017), Encode-decoder self-attention block and Feed Forward neural network.

In our current approach number of beams are considered as 5 to provide more than one choice to user on IDE while auto code completion.
Transfer Learning
Transfer learning is when a model developed for one task is reused to work on a second task.
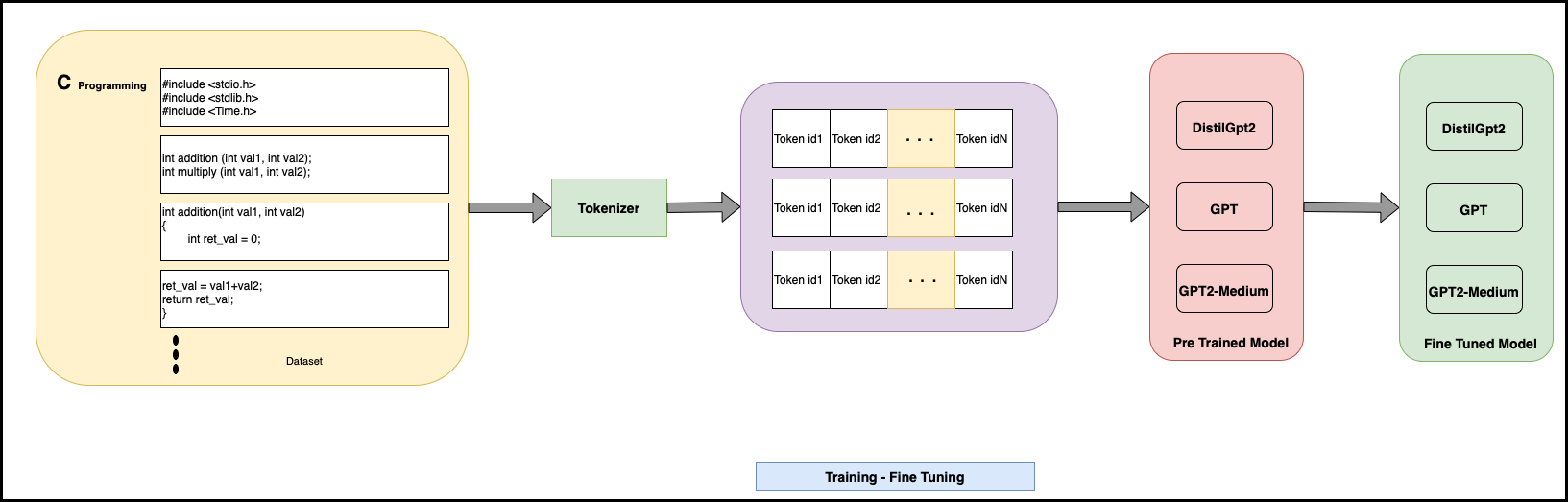
In our project Transfer Learning is done on GPT-2 model with transformer library from huggingface and its been done using google colab pro subscription due to higher GPU requirements. Google Drive is used to keep Dataset and notebook file due to google's ecosystem. C Programming Dataset is used for Autocode project. Any other dataset can also be used.
For Transfer Learning, C program database is selected and passed through tokenization processes. Here files will be divided into multiple token ids and then pass through pre-trained model which are distilgpt2, gpt & gpt2-medium. In the end modified modle with Transfer Learning will be generated and used in inferencing process.
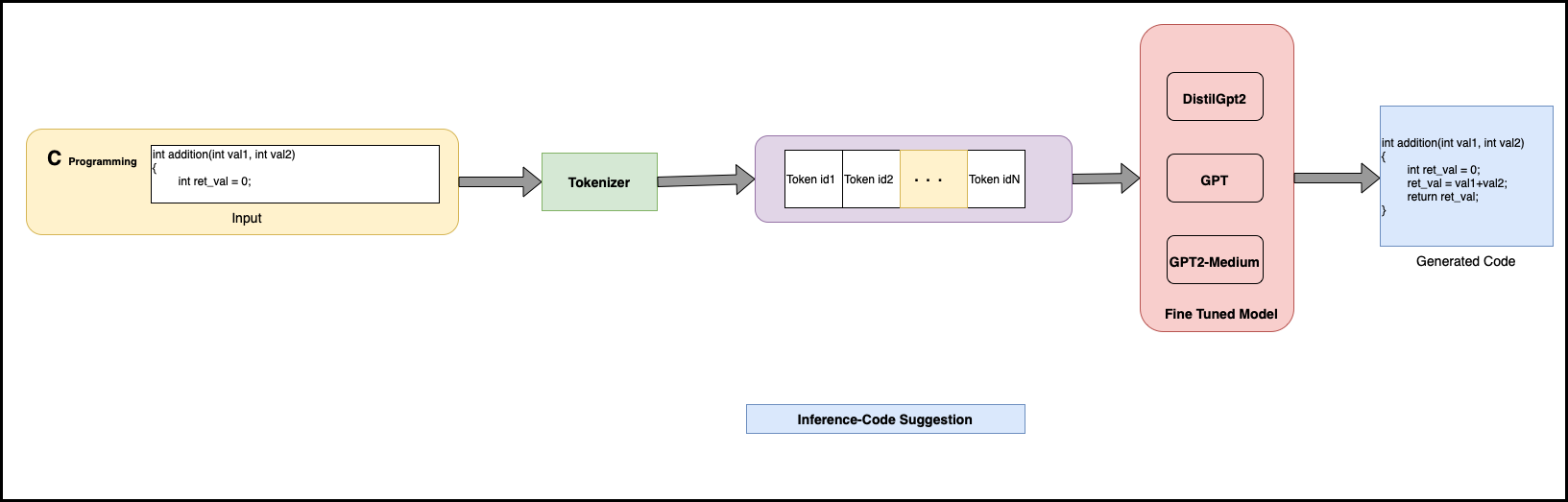
In Inferencing process, small code snippet will be used as input and then processed through tokenizer and then given to fine tunned model. Here to provide more choice to user five outputs (beam number = 5) is considered. Once outputs are generated then are given to sublime text plugin (Modified) to be presented on screen.
Overall Performance
| S. No. | Model Name | Train Loss | Validation Loss |
|---|---|---|---|
| 1 | Distilgpt2 | 0.721536577 | 3.044954 |
| 2 | GPT2 | 0.4862 | 4.195924 |
| 3 | GPT2-Medium | 0.2594 | 1.307671 |
Model Test Report
Considering better training loss and validation loss, GPT-2 Medium model is considered for further inferencing.
| S. No. | Product | Inference Time | Memory Consumed | Model Type |
|---|---|---|---|---|
| 1 | Tabnine | 30msec | 692 MB | GPT2 |
| 2 | Auto-Suggest | 37msec | 3383msec | GPT2-Medium |
Performance Benchmark
Inferenceing Performance data measured with i5 RAM 16GB with Nvidia 1050Ti GPU. This data may vary on different machine.
Output
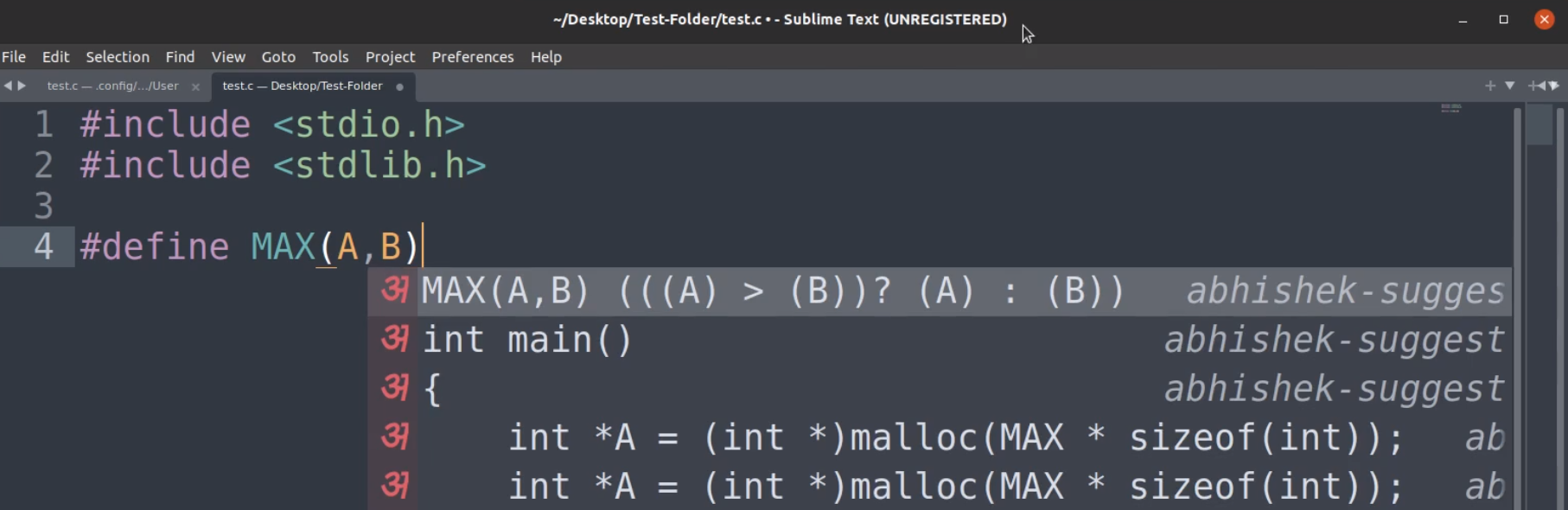
Sample output with SublimeText IDE.
Tools used
- Google Colab pro (To get online gpu for better performance)
- Google Drive (To store and link code, dataset and model files with Colab)
- Sublime IDE (Used for Inferencing)
- Transformer library (GPT2 pre-trained models from huggingface)
- Nvidia's 1050Ti GPU (For Inferencing)
- Drawio (To create diagrams)